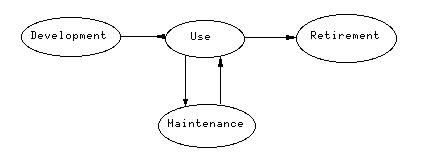
Reducing the cost of maintenance may increase the development cost but should greatly reduce the overall cost of the project. One sign of a mature development effort is the realization of the long term lifetime and costs of a project. Eventually, the code gets too hard to fix or to add new features to and it gets retired and a new program is written.
Think about the whole lifetime cost, not just the cost of developing the initial release. Small efforts during design and development can mean big reductions in maintenance cost. Documentation, modeling and processes are ways to help this.
This rarely works in the real world and since the process doesn't allow for going backward, it is expensive when to have to. It can take hundreds of times more effort to fix a design problem if it is caught in testing than if it is caught in design. The waterfall model has too much control, where the build and fix model has too little.
It is built on the idea that we refine the definition of the system from high levels of abstraction to low. We start by breaking the system down into pieces during architectural design. Each piece is defined and its responsibilities and relationships with other pieces is determined. This is similar to defining classes.
Each piece goes through the refinement cycle. This takes the system piece through the steps from a high level design to code. This cycle can be repeated if problems are found. We can also run the system pieces through the process in parallel as we know the relationships between them. This is similar to how different classes can be coded separately once we have defined the methods. Let's look at the steps in the refinement cycle.
Brainstorming is actually a formal process. It involves a group of people all contributing ideas about a problem. All suggestions are recorded and no discussion of them is allowed. We collect the ideas and analyze them later.
Objects can be physical things, like tables, rules, like gravity, actions, like falling and abstract things like errors. We can also have objects that represent roles for things, places, containers, events and data sources and sinks. Look for nouns and verbs in the requirements.
Then start generalizing the objects into classes. You may eliminate objects at this time or even add them to represent abstraction that don't have a real existence. Remember that classes can exist in the hierarchy just to hold common methods and data. You may also split objects found in the brainstorming into several classes.
There are design languages like UML (Unified Modeling Language) that are designed to help document the relationships between objects.
for each element in the array is this the one we want? if yes print it and exit if not check the next one end for print that it wasn't there
If the code in this piece used code in other pieces, you may have to write stubs for them. Stubs are classes and methods that look like the real thing but aren't complete. For example, a method that is supposed to count the number of characters in a file might not have been written yet. So we write one that has the same signature but always returns 42. This allows us to test our part even if the rest isn't built yet. We should try to break the system into parts so this isn't needed.
One common prototype is to build the GUI to test it on users. The prototype would have all the controls but none of the backend processing. Stubs are built to simulate the actions. Prototypes need not even be code. You could construct storyboards or hand-drawn pictures of the GUI components and present them to the users and get opinions.
Prototypes can be used to find inconsistencies in the requirements or design. They should be tossed out after the experiment is completed. You should resist the temptation to reuse the prototype code in the final project. Prototype code is usually written quickly without regard to quality, clarity or error handling.
In the early, pre-code, stages this takes the form of reviews of the documents that are produced as part of the stage. For example, the document that contains the requirements is examined closely by a team of people that are familiar with the problem area. This often includes customers. Each requirement is examined in turn. You are looking for whether the requirement is needed, is clear, complete or if it is in conflict with other requirements.
The design document is reviewed as well. Here we are looking that the requirements are met, or at least covered. We look for conflicts between components, feasibility, efficiency, fault handling, performance, etc.
A walkthrough is a process for reviewing code or design. The author(s) present the code or design and explain the decisions that led to it. They present examples and scenarios of how it would be used. The reviewers look for common problems, inconsistencies and other problems. A code inspection is more formal. The code is examined line by line, looking for errors in use and whether the code performs the actions it is supposed to.
In both cases, the problems are notes but not solved. The purpose is to find the errors, they will be solved later. Problems can be classified into what part of the process they were introduced or by severity.
By contrast, white box involves detailed knowledge of the code. This is what we described above under unit and integration testing.
There are some techniques that can be used to help find errors in the code or design. One is to consider equivalence classes. For a given method, there is a range of values it can take as arguments. This range can be broken into classes. In each class, the response of the method is the same or similar for any member.
For example, if a method takes integer arguments, we don't (and probably can't) try every possible value or combinations of values. But, there are groups of integers that have common effect on the method. It probably reacts the same to all positive numbers and all negative numbers so we only need to try a couple of examples from each class. Include some small and large values from each class. The boundaries between classes are the most interesting. Boundaries and interfaces are where most errors occur. So we might use a set of values like -999999,-500, -1, 0, 1, 500, 99999.
Measuring the completeness or effectiveness of testing is difficult. There are methods to determine the coverage of the tests. We can instrument the code (add extra code to record activities) and run the tests. Then we record which statements in the code got executed when the tests are run. We can try for complete statement coverage but this is not always possible. It can be difficult to simulate some system errors to test the error handling.
Another measure is to determine if every path through the code has been followed. We have to have test cases to exercise both branches in if statements or all cases in a switch statement.